Data Streaming Accelerators
![]()
1. Summary
Dynamic Interval Management
The theoretical lower bound for merging \(N\) static intervals is \(\Omega(N \log N)\) due to the sorting requirement. By focusing on interval edges rather than the source intervals themselves, we can focus on efficient algorithms with compact implementation. However, in Online Streaming Environments, the task shifts from batch data loading (static intervals) to streaming data ingestion (dynamic intervals).
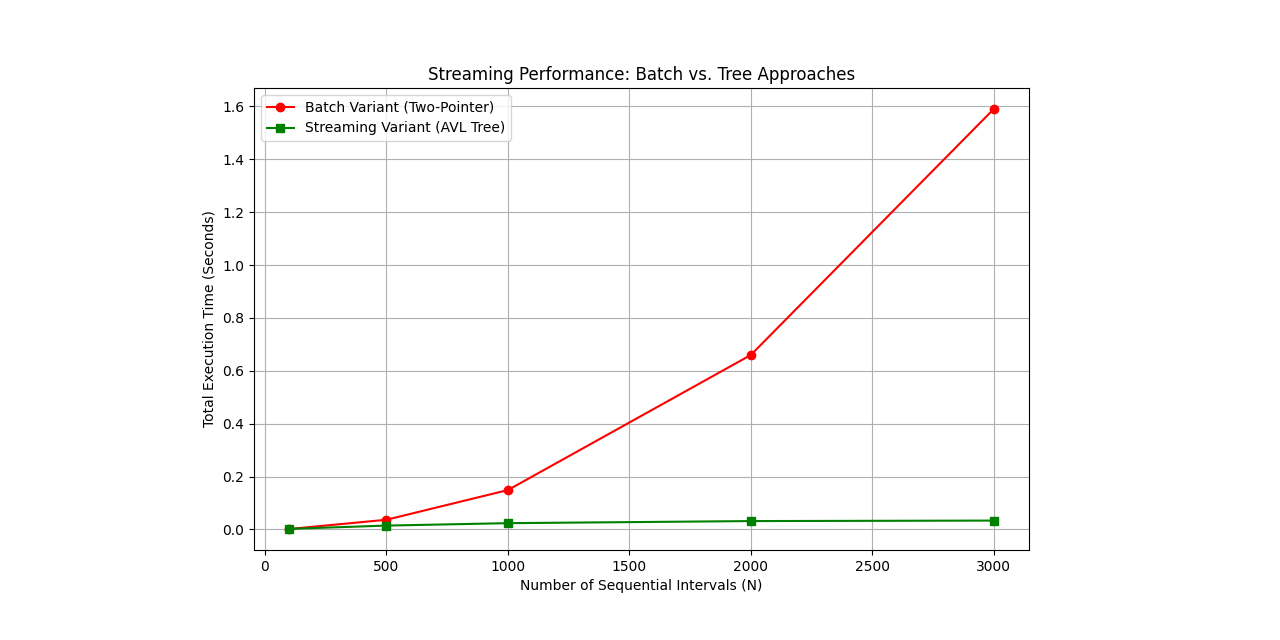
Dynamic Point Aggregation
The optimal runtime complexity for dynamic point aggregation from \(N\) point values to \(O(N)\) disjoint intervals is \(\Omega(N \log N)\) due to the ordering requirement. The request handler uses put requests to add new values and get requests to make a new interval sequence.
Because offline scenarios (batch data) have known usage patterns, the batch variant (V1) can optimize the hot path by simplifying high-usage put requests to \(O(1)\) and expanding low-usage get requests to \(O(N \log N)\).
However, because online scenarios (streaming data) do not have known usage patterns, the streaming variant (V2) must instead balance complexity between put requests (\(O(\log N)\)) and get requests (\(O(N)\)).
Suffix Pattern Recognition
For suffix pattern recognition with \(K\) suffix patterns (length \(W\)) and 1 query pattern (length \(N\)), using reverse-traversal prefix tree search is efficient because it can model common ancestor ordering with reverse encoding (by inserting suffix patterns in reverse order during setup and searching in reverse order during queries) and check the multiple patterns over a single root-to-leaf pass (taking runtime \(O(K \cdot W)\) for one-time setup and \(O(W)\) for each query). This improves over using direct suffix pattern search which must check the multiple patterns over separate array passes (taking \(O(K \cdot W)\) for each query) or using forward-traversal prefix tree search which cannot model common ancestor ordering and must check the multiple patterns over separate root-to-leaf passes (taking runtime \(O(K \cdot W)\) for one-time setup and \(O(K \cdot W)\) for each query).
For batch data (offline scenario), reading the query pattern from a static array (size \(N\)) with a reverse iterator takes \(O(1)\) auxiliary space. For streaming data (online scenario), reading the query pattern from a history array (size \(W\)) reconstructed from the stream takes \(O(W)\) auxiliary space.
2. Getting Started
This suite requires Python 3.13+.
To run the regression tests:
uv run --group dev --extra benchmark pytest -sv